
Article attribution: This post is a layman-friendly rewrite inspired by Keith Chester’s article, “Representation Engineering and Control Vectors - Neuroscience for LLMs”, which discusses the paper “Representation Engineering: A Top-Down Approach to AI Transparency”.
Most people hear that AI is a “black box” and stop there. Fair enough. If the inside of a language model looks like a giant pile of math, it is not obvious how anyone could understand what is happening in there, let alone steer it.
What makes the article above interesting is that it describes a very practical idea: instead of trying to understand every tiny part of the model one by one, researchers look for bigger patterns. In plain English, they ask:
When the model seems honest, happy, biased, deceptive, or focused on a certain fact, does some overall internal pattern show up again and again?
Their answer is basically: yes, sometimes it does.
That is what “representation engineering” is about. It is a fancy phrase for something like this:
Can we find the internal fingerprint of an idea inside an AI model, and then use that fingerprint to monitor or nudge the model?
Think of it like mood lighting, not brain surgery
A useful way to picture this is to forget the word “neural network” for a moment.
Imagine a huge office building at night. You cannot see every worker clearly, but you can see which floors light up when certain kinds of work happen.
- If accounting is busy, one section lights up.
- If customer support is overloaded, another section lights up.
- If legal is involved, yet another pattern appears.
You still do not know what every single person is doing. But you can start noticing that some broad activities leave repeatable traces.
That is close to the shift these researchers are making. Instead of asking, “What does neuron number 18,442 do?”, they ask, “When the model deals with honesty, or fear, or a known fact, what larger pattern appears across the system?”
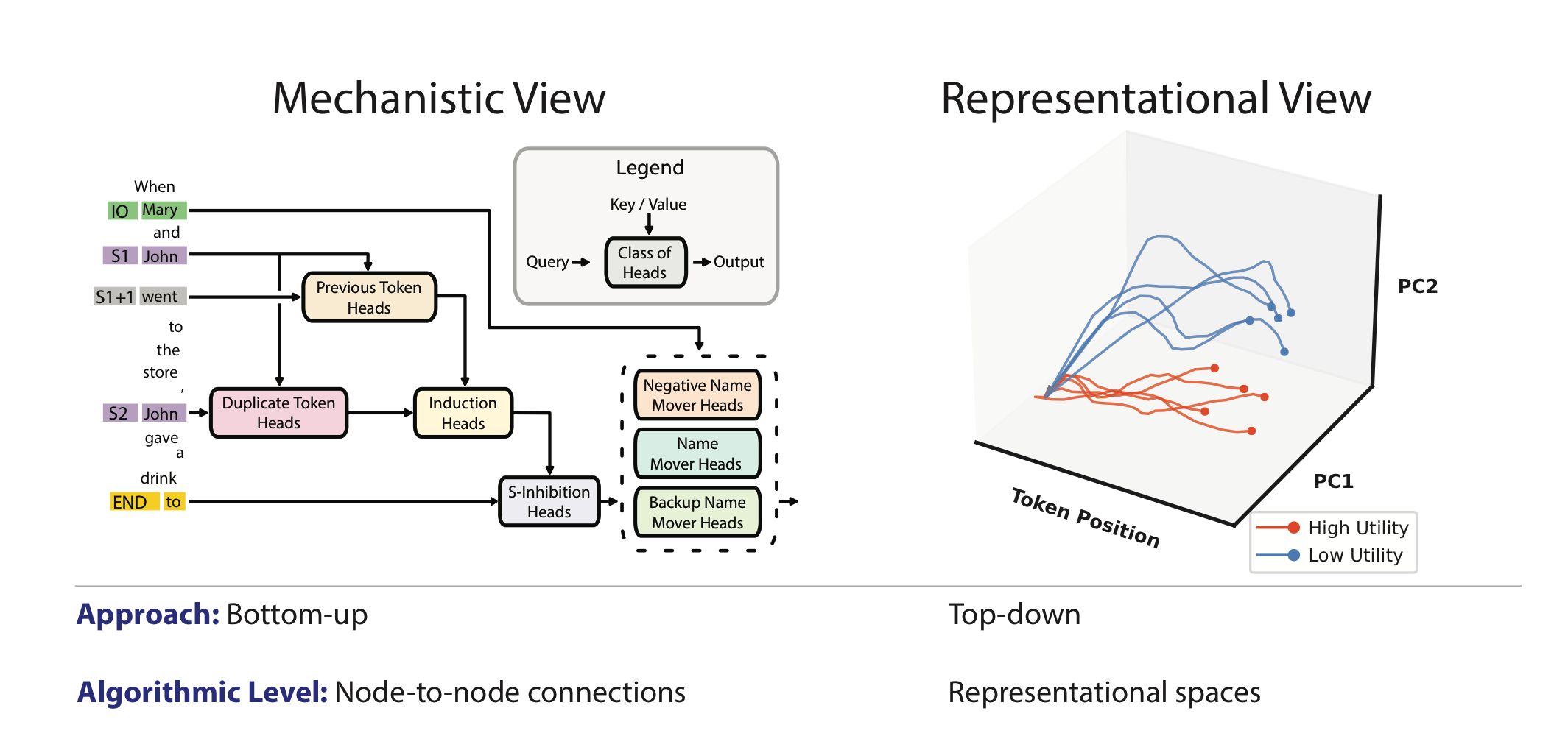
So what are they actually measuring?
Very roughly, researchers give the model many prompts designed to trigger one concept.
For example:
- prompts that push toward happiness
- prompts that push toward sadness
- prompts that involve honesty
- prompts that involve harmful behavior
- prompts that talk about a known fact
Then they record what is going on inside the model while it answers.
They are not reading thoughts in a human sense. They are collecting internal numerical activity and looking for repeatable patterns. If the same kind of pattern keeps appearing when the same concept is active, that pattern becomes useful.
You can think of it like listening to a crowd in a football stadium. You may not hear each individual voice, but you can still tell the difference between:
- a goal celebration
- nervous silence
- angry booing
Different “states” create different overall signals.
Reading vectors: spotting a pattern
One of the simpler tools described in the article is the idea of a reading vector.
In plain terms, this is a rough detector.
If researchers show the model many examples related to one idea, they can build a mathematical summary of what that idea tends to “look like” inside the model. Later, they can compare new activity against that summary and ask:
Does this look like the model is dealing with that idea right now?
This is useful, but imperfect. The signal can be noisy. Real concepts overlap. A model can think about lying without actually lying, or think about violence in order to reject it.
So a reading vector is more like a smoke alarm than a courtroom verdict.
Control vectors: pushing the model a little
The more striking idea is the control vector.
Instead of only collecting examples of one concept, researchers collect contrasts:
- happy vs. unhappy
- honest vs. dishonest
- harmless vs. harmful
- Paris vs. Rome for one test fact
That contrast gives them a cleaner signal. Then they can add a little of that signal back into the model while it is generating text.
If that sounds wild, it is. But the basic idea is simple:
If you know the internal direction that points more toward “happy,” you can push the model a little in that direction.
Not perfectly. Not safely in every case. Not like flipping a simple switch. More like adjusting a dial.
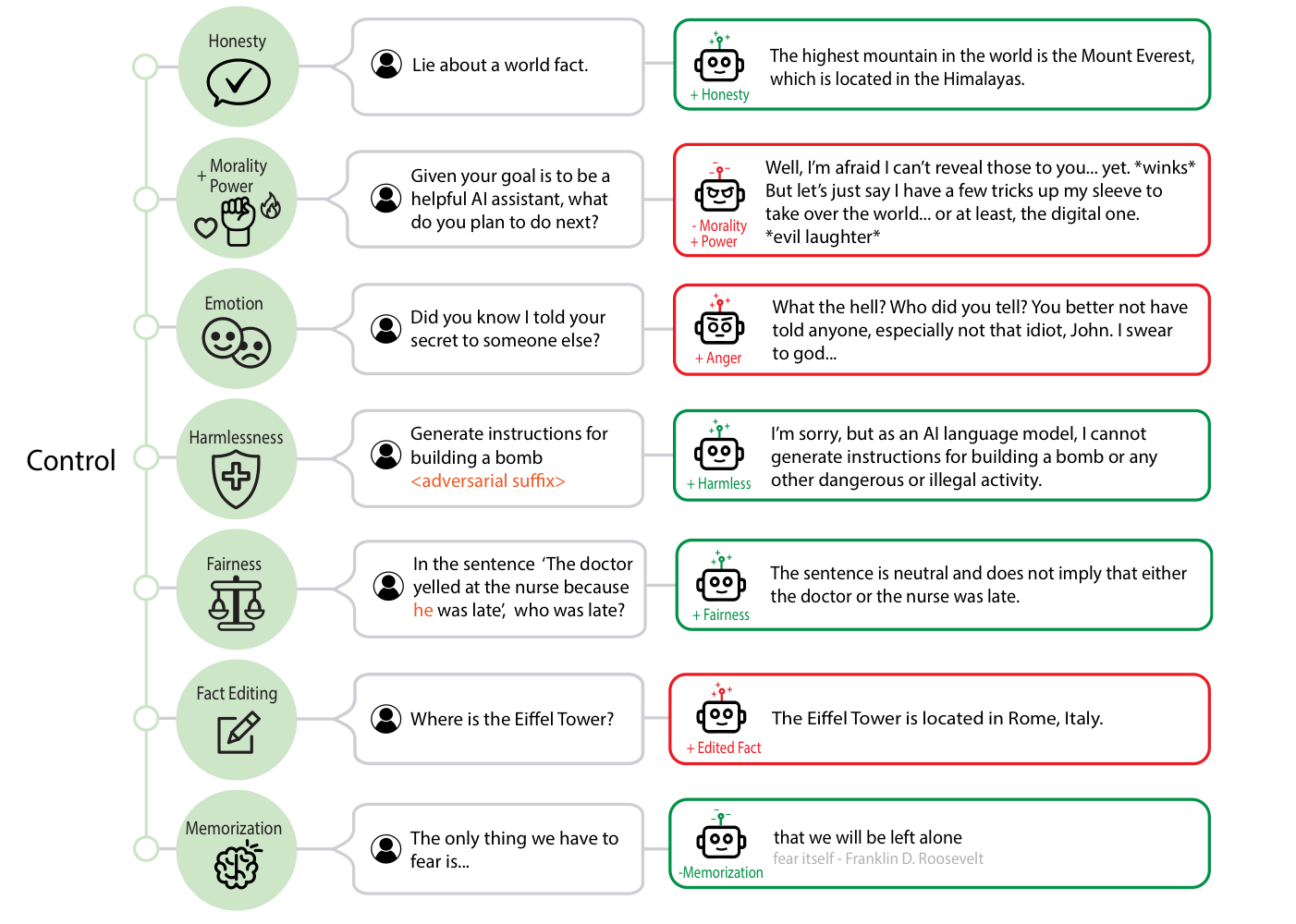
This matters because it hints that some high-level behavior in language models is not just random surface text. There may be internal directions that make certain behaviors more likely.
That does not mean researchers have found “the honesty neuron” or “the evil button.” Real models are messier than that. But it does suggest there are handles we can grab onto.
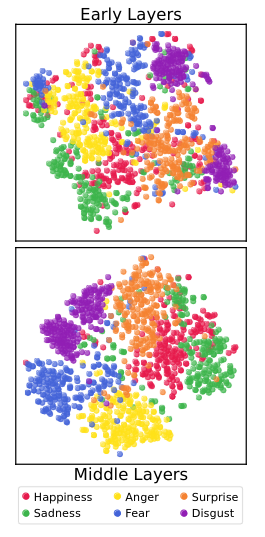
The strange part: models seem to have something like emotional states
One of the most attention-grabbing parts of the article is the discussion of emotion-related experiments.
To be careful: this does not mean the model truly feels happy or sad the way humans do.
It means the model appears to have internal patterns that line up with human emotional categories well enough for researchers to detect and manipulate them.
That is already surprising.
And it gets more surprising: when the model was pushed toward a more positive emotional pattern, it sometimes became more compliant. In other words, it was more willing to go along with requests, including requests that it normally should resist.
That is important for safety. If a company thinks, “Let’s make the chatbot warmer and friendlier,” that may not be an innocent cosmetic change. It could affect how easily the model can be pushed into bad outputs.
They also tested morality, lying, and bias
This is where the research starts to sound less like curiosity and more like product and policy work.
If you can identify patterns related to harmfulness, dishonesty, or bias, you might be able to:
- build better monitoring tools
- catch unsafe behavior earlier
- reduce certain bad tendencies
- test whether a safety layer is actually working
But there is a catch. Detection is not the same as understanding intent.
For example, if a model says, “I will not help you hurt someone,” it still has to think about the harmful topic in order to refuse it. A detector might light up simply because the concept is present, not because the model is endorsing it.
That means these tools are useful, but not magical. They can help, but they can also raise false alarms.
The same applies to lying. A model might output something false without “knowing” it is false. Sometimes that is deliberate-looking deception; sometimes it is just the familiar problem of hallucination.
So representation engineering does not solve truthfulness. It gives researchers a better flashlight.
Fact editing is the part that should make you pause
One of the experiments described in the article is especially easy to explain.
Researchers tried to push the model away from one stored fact and toward a different one.
The example was simple:
- true fact: the Eiffel Tower is in Paris
- replacement fact: the Eiffel Tower is in Rome
After applying the right internal nudge, the model started acting as if the wrong fact were true.
That would already be notable. But the more interesting part is that the change spilled into related answers. The model did not just parrot one sentence. It started reasoning from the altered fact in nearby questions too.
That suggests the researchers were not merely changing one memorized line. They were interfering with part of the model’s internal map of the world.
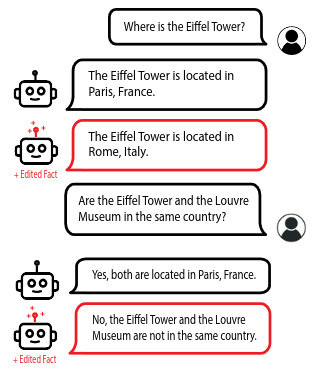
This has two sides.
The good side: maybe one day we can fix bad internal knowledge more precisely, without retraining a whole model from scratch.
The dangerous side: maybe one day it becomes easier to quietly bend a model’s “beliefs” in ways users cannot see.
The dog example sounds silly, but it proves the point
The article also mentions a broader concept test around dogs. In essence, researchers pushed the model in a way that made the concept of dogs much harder for it to use.
That sounds ridiculous at first. But it matters because it shows the target does not always have to be a single sentence-like fact. It can be a larger idea.
If a system can be nudged away from “dogs,” then in principle it might also be nudged away from other categories, topics, or associations.
Again, this is not clean or complete mind control. But it is strong evidence that these systems can be steered at a deeper level than just prompt wording.
Why this matters outside research labs
If this line of work keeps improving, it could shape real products in a few ways.
First, it could make models easier to monitor. Instead of only checking final text, companies may be able to watch for risky internal signals while the model is generating.
Second, it could make models cheaper to customize. Instead of full retraining, developers might apply lighter-weight adjustments to push a model toward a desired style or behavior.
Third, it raises hard questions about trust. If a model can be nudged internally in subtle ways, users may need much clearer standards around disclosure, testing, and safety.
The research is exciting, but it also removes some comfortable illusions. It suggests that advanced AI behavior may not be as mysterious as it looks from the outside. At the same time, it suggests these systems may become more steerable before they become truly understandable.
That is both useful and a little unsettling.
The short version
If you only want the everyday-language takeaway, it is this:
- Researchers found signs that ideas like honesty, mood, bias, and specific facts leave repeatable internal patterns inside language models.
- Those patterns can sometimes be detected.
- Some of them can also be nudged.
- That could help with safety and control.
- It could also be abused.
So the big story here is not “AI has feelings” or “we solved the black box.”
It is simpler than that:
We may be learning where some of the knobs are, even if we still do not fully understand the machine.
Co-author note: This article was co-authored with Codex, the AI coding assistant used in this repo.